crxjsとは Chrome Extensionを作るためのツールです。
しかし公式のドキュメントには、まだfirefoxのpluginを作る方法は記載されていません。
ただ以下のようにすでにPRはマージされており、使えるようになっています。
ということで、firefoxでcrxjsを動かす方法を見ていきたいと思います。
Create Project
基本は公式のドキュメント通りですが、いくつか足りないものがあるので順を追って書いていきます。 また今回は Vite2のバージョンで記載していきます。
npm init vite@latest npm install npm i @crxjs/vite-plugin@2.0.0-beta.23 -D // latestだと1系が入ってしまう npm i @types/firefox-webext-browser -D // browser objectを使うため
まずは上記コマンドでpluginたちをinstallします。
Chrome Extensionとは一定互換性があるのですが、Chromeは chrome namespaceを WebExtension APIでは browser namespaceを使います。
Firefoxは chrome namespaceでも動くのですが、 非同期のAPIのコールバックの渡し方が違います。
設定ファイル
各種設定ファイルを修正していきます。
config書き換え
拡張機能を作るには、manifest.json を設定しなければいけません。 crxjsの公式ドキュメントには jsonファイルを設定するやり方が書いてありますが、型の恩恵を受けるために ts上に直接記載していきます。
以下は vite.config.ts を書き換えたものです。
import { defineConfig } from 'vite'; import react from '@vitejs/plugin-react'; import { crx, defineManifest } from "@crxjs/vite-plugin"; const manifest = defineManifest({ manifest_version: 3, name: "My Extension", version: "1.0.0", action: { default_popup: "index.html", }, }); // https://vitejs.dev/config/ export default defineConfig({ plugins: [ react(), crx({ manifest, browser: "firefox" }), ] })
これで最小限のmanifestは完了です。
package.json修正
tsで作成している場合は、以下のように type module を指定する必要があります。
指定しない場合、ts buildでTypeErrorになってしまいます。
{ "name": "my-extension", "type": "module", "scripts": {}, ... }
こちらはいずれ解決するかもしれません。
実際に動かしてみる
まずビルドします。
npm run build
ビルドしたら about:debugging#/runtime/this-firefox にアクセスして 上記でビルドした dist/manifest.json を指定して開きます。

読み込むとこんな感じになります。
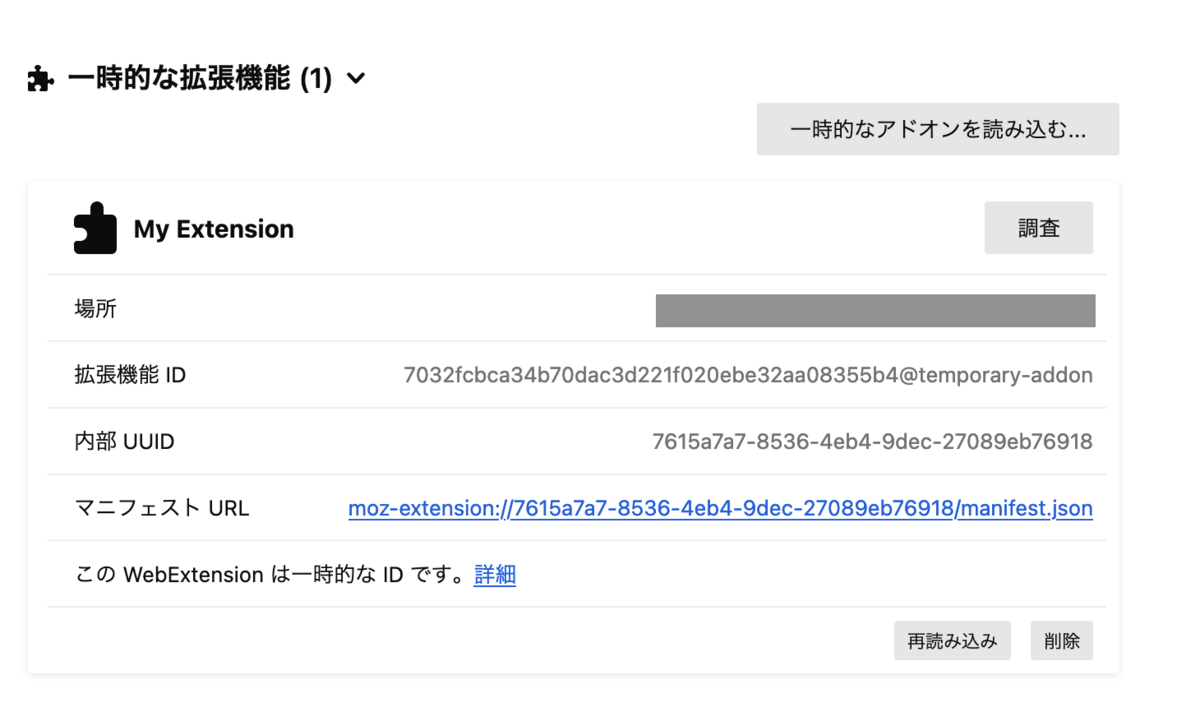
読み込ませると以下のようにアドオンを開けるようになります。